
Estimating “known unknowns”
There's a famous quote from former Secretary of Defense Donald Rumsfeld:
“ … there are known knowns; there are things we know we know. We also know there are known unknowns; that is to say we know there are some things we do not know. But there are also unknown unknowns – the ones we don't know we don't know.”
 |
I write this blog. I'm an engineer. Whilst I do my best and try to proof read, often mistakes creep in. I know there are probably mistakes in just about everything I write! How would I go about estimating the number of errors? The idea for this article came from a book I recently read by Paul J. Nahin, entitled Duelling Idiots and Other Probability Puzzlers (In turn, referencing earlier work by the eminent mathematician George Pólya). |
Proof Reading2
Imagine I write a (non-trivially short) document and give it to two proof readers to check. These two readers (independantly) proof read the manuscript looking for errors, highlighting each one they find.
Just like me, these proof readers are not perfect. They, also, are not going to find all the errors in the document.
Because they work independently, there is a chance that reader #1 will find some errors that reader #2 does not (and vice versa), and there could be errors that are found by both readers. What we are trying to do is get an estimate for the number of unseen errors (errors detected by neither of the proof readers).*

*An alternate way of thinking of this is to get an estimate for the total number of errors in the document (from which we can subtract the distinct number of errors found to give an estimate to the number of unseen errros.
Definitions
We're going to asume that the proofers only find (or don't find) actual errors in the document. We're ignoring the possibility of a false-positive responses (where a proofer indentifies a mistake that is not really a mistake).
Let's define some variables:
n is the actual number of errors in the manuscript (total).
n1 is the number of errors found by reader #1.
n2 is the number of errors found by reader #2.
b is the number of errors found by both proof readers.
u is the number of unseen errors (the number we are trying to estimate).
Thought experiments
If the number of errors found by both readers is high (with a relatively small number found distinctly independant), then there is a good chance that there are not many unfound errors (A high correlation between the found errors indicates that most have been found).
Similarly, if there is a 'good' proofer (someone who has great skill and finds errors with high probability), this would suggest that the errors s(he) found is close to the actual number, and by comparing to the other proof reader we can estimate how 'good' they are by the number found by the second not found by the first.
Interestingly, as we will see, we can make an estimate about the number of unseen errors based purely on the count of the errors, and this estimate is agnostic of the skill of either of the proof readers, and independent of the document length!
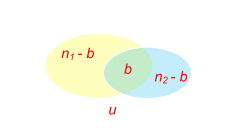 |
There is a simple relationship between all the errors from basic set theory: n = u + n1 + n2 − b |
This makes total sense. The total number of the errors in the document is equal to the number of unfound errors, plus the number found by each proofer, subtract the number found by both (we don't want to double count).
Next we need to examine how the proofers find the errors. Below is a digram showing all the errors in the manuscript. We make the assumption that there is an fixed independent probability of each proofer finding an error.

For the first reader, this is probability P1. For the second reader, this is probability P2.
Mathematicians call these Bernoulli Trials. The error is found, or it is not. The probability that any one error is found is found by the first proofer is P1, the probability that it is not found is (1 − P1).
These probabilities are equal to the number of errors found over the total number of errors that could be found.
P1 = n1/n P2 = n2/n
And since the proofers read independatly, the chances of them finding both is logical AND (we multiply probabilities)
P1P2 = b/n
These Bernoulli trials will have a binomial distribution and (for n>0) the expected number of errors can be given by the formula:
n = (nP1)(nP2) / (nP1P2)
n = (n1)(n2) / b
Substituting this back into the formula from the set theory we get:
(n1)(n2) / b = u + n1 + n2 − b
u = (n1n2)/b − n1 − n2 + b
u = [(n1−b)(n2−b)]/b
And here we have the result. Using just the number of errors found by each proofer it is possible to estimate the number of unfound errors in a document. This formula is independant of the skill of either proofer, and independant of the length of the document. Nice!
Example
 |
Imagine I print out two copies of a short story I've written and give these copies to two friends. The first finds 10 spelling mistakes. The second friend finds 12 mistakes; eight of which are errors that they both caught. Using our formula, the estimate for the number of unseen errors in ((10-8)(12-8))/8 = 1, so there's a good chance that there is another error, unseen, in the document. |
Similar uses
These ideas do not have to apply to just finding errors; they can be used to estimate population in 'Tag and Release' experiments.
 |
Imagine you are trying to estimate bird populations on a remote island. On the first day, you capture 180 birds at random, and put non-invasive ID tags around their legs. You then release them. You come back two days later, and this time catch 120 random birds. Of the birds caught, 90 of them have ID tags. From these data points it is possible to estimate the size of the bird population. In the second capture 90/120 birds had tags suggesting that 75% of the population have tags. So 180 tags birds tagged on the first day represents 75% suggesting that the population of birds is approximately 240. |
|
If you know items are labelled sequentially it's possible to apply modified techniques. I wrote about this last year to estimates the number of people running in a marathon, and the most famous example of this is the application, during the Second World War, of estimating the number of German tanks procuced by examing the serial numbers of captured and destroyed tanks. |

|
Related Articles
Here are some other articles that also consider sampling and imperfect views on collections to make estimates:
The Sectrary Puzzle (also sometimes called the interview puzzle, or the wife, or husband finding puzzle), deals with how to give the best chance of selecting the best person for a role when you are only allowed to see each person once. You interview a candidate once then have to give a hire/no-hire call and if you pass, you are never allowed to go back. At the start you have no idea of the spectrum of candidate qualifications, so you want to see a 'pool' of people first to judge the range. The larger the pool you consider before setting your threshold the better your accuracy, but then you are reducing the people you'll get to select from. Conversely, a smaller sample pool might give you enough of an accurate sample of the candidates. What is the optimal? …
Simpson's Paradox deals with the interesting way that answers can be inverted when comparing samples with different denominators.
By adjusting boundaries around which sampling can occur you can influence results. This is called Gerrymandering.
With imperfect information, what is the optimal strategy for playing the game Deal-or-NoDeal?
There is a danger that if you stop too soon in looking for errors you might get the wrong inpression of the average number of errors in the entire document. Maybe there is a higher concentration of errors in the first part of the document? If you visit a sports game, and a good percentage of the points are scored in the first part of the game, it might bias your opinion of the overall game. Here is an article which talks about, if you eventually win a game, what is the percentage chance you were winning the entire game (Bertrand's Ballot).
Here's a short primer on confidence levels and the central limit theorem.
What is the difference between Risk and uncertainty?
Finally, why there is no such thing as the Conservation of Luck.
You can find a complete list of all the articles here. Click here to receive email alerts on new articles.
Click here to receive email alerts on new articles.
© 2009-2015 DataGenetics Privacy Policy