
Default Photograph Names
|
Most of us own a digital camera; most likely you have a couple of them (plus a smartphone or two that takes pictures!) Over the last couple of years you’ve probably accumulated hundreds, or possibly thousands, of digital photographs. |
 |
 |
IMG_0123.JPG
 |
IMG_0123.JPG and IMG_0124.JPG do these names sound familiar?* By default, digital cameras start off with a base filename and increment a post-pended number with each exposure.
*Another popular prefix is DSC and your hard drive might be full of images that look like DSC_0123.JPG |
|
If you’re like me, you never bother to change any of your camera parameters; you simply snap-away then drag-n-drop the files off to your computer for storage and/or to the cloud. (Typically at random intervals, or maybe at the end of a vacation or trip). Even after I’ve download images to my computer, I very rarely rename any of the files, so my computer has many duplicated image filenames. When you purchase a new camera, images typically start being recorded with the filename IMG_0001.JPG and increase from there. |
 |
Distribution of filenames
|
I was curious if other people did a similar It seems that even semi-professionals and passionate amateurs don’t often rename their submissions. Then, I became more curious about the distribution of filenames. How many are labeled IMG_0001.JPG how many are labeled IMG_0002.JPG … ? |

|
 |
Do people upload all their photos, or just their ‘good’ ones? If they upload all of them, then the quantity of photos per filename should decrease as the filenumber increases – If there is no IMG_0099.JPG then there will not be an IMG_0100.JPG from the same upload). Working against this is the fact that, whilst many cameras reset their filenumber back to 0000 after transfer, many have the option to make the current filenumber the programming equivalent of a STATIC variable and remember it even after the current images are transferred and removed (so only rolling around and repeating filenames after 10,000 images have been taken). |
My curiosity about this led me to compose a couple of lines of code to script some requests to the search page on flickr and record the reported number of images matching. I obtained the number of images stored on the service for all filenames from IMG_0001.JPG to IMG_9999.JPG

The number of matching images is displayed as part of the search results, and automation is our friend.
Results
10k data points are a lot to plot as a histogram, but I want to represent all the data I've plotted it all here are best I can as a line chart.
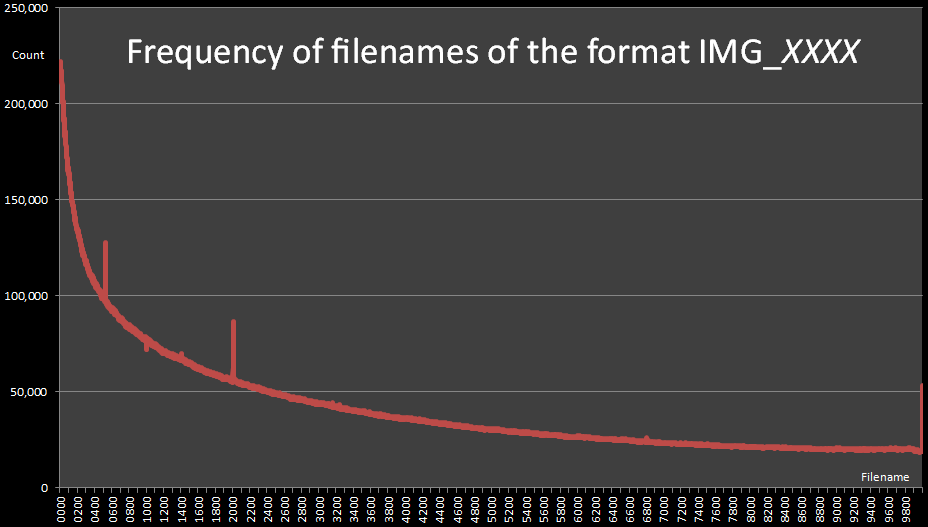
It's a beautiful logarithmic decay, with a couple of glitches.
|
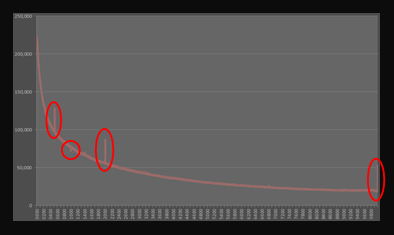
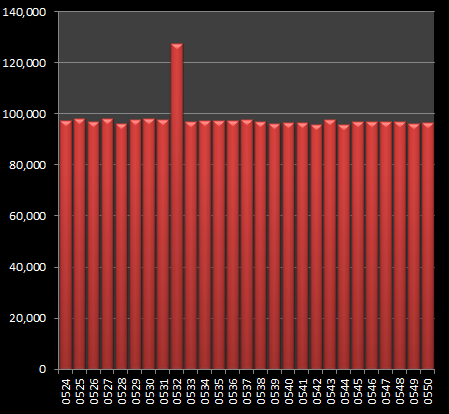
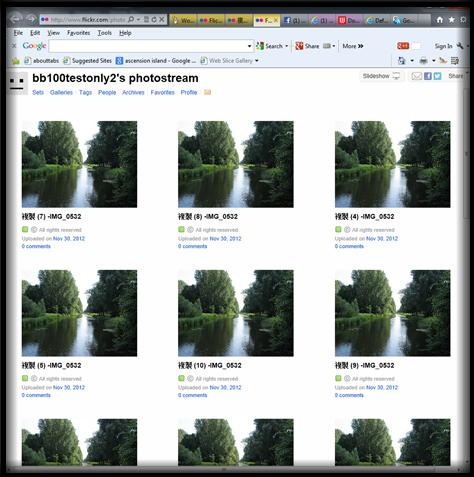
(I've included close-ups of each glitch below, and highlighted them on the right) The first glitch occurs at IMG_0532. I'm stumped as to the cause of this one. I can think of nothing significant about this number, and why photographs with this filenumber occur with a frequency 30% higher than numbers directly either side! Outside of some indexing issue on the flickr server I'm at a loss. If anyone knows (or would like to speculate a reason), drop me an email and I'll be happy update this article. UPDATE - See end of article The next glitch occurs at IMG_1000 where there is a slight fall. As this number is a round number I can speculate that people might want to rename this particular file. It's a much smaller glitch than the previous, being just an 8% deviation from the curve. |
 |
 | 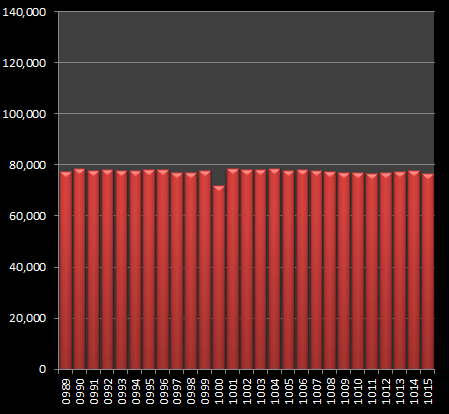 |
| IMG_0532 | IMG_1000 |
There's a very interesting ‘lump’ between the range 2007 – 2012. Obviously this represents the images that people have renamed to a year because of significance of the image taken in that year. The peak of the lift is over 50% higher than the surrounding curve.
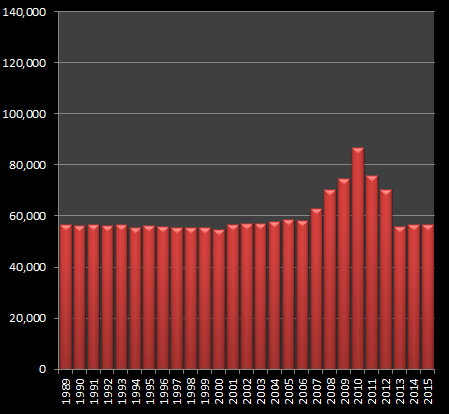 | 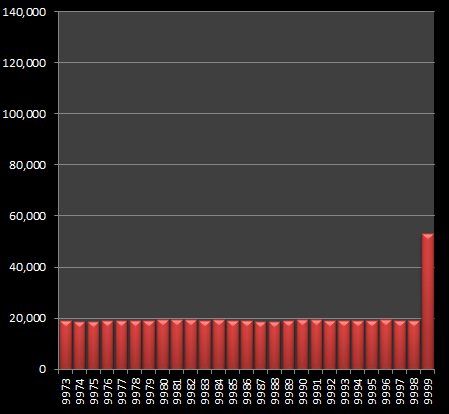 |
| Years | IMG_9999 |
Finally, there's a large spike at the end for IMG_9999 Again, because of the significance of this number (being at the top of the allocation), its not a stretch to imagine people renaming an image to this before uploading (either because it is easier to remember, or as an attempt to stop a collision with another filenumber if you can't remember your current high-water-mark of images and want to simply select the largest possible).
Logarithmic Decay
After removing the outliers, and plotting a trend-line through the data we can see that there is a very strong correlation (R2 over 98%) between the search results and logarithmic decay.
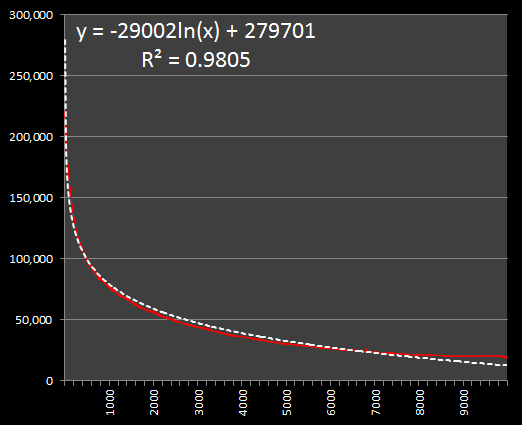 |
Logarithmic decay is fascinating in that it appears far less often in analysis than its well-known cousin the exponential decay. Many physical parameters decay in a mathematically exponential way because of the nature of the situation. Exponential decay models, in a simple form, the concept of survivability, where a certain number of items exist and there is a probability of each element decaying at each time interval, leaving less from that point on. In logarithmic decay, there is an initial rapid decline, then a slowing of the rate. One other example of a logarithmic function is Benford's Law, which I wrote about earlier this year. If you think about it, the number of photographs with a particular filenumber is not a function of decay from previous filenumbers like some form of radioactive decay (which exponential decay would model). Instead it’s an additive representation of a superposition of ordered ranges of numbers. Let me explain more with a thought experiment … |
If you have a collection of photos and select to upload them all, and the highest numbered photo you have is 1263, then if you upload all these photographs, all filenumbers from 1 – 1263 are increased by one. Someome else with a different range of photos will upload theirs (say from 1 – 463). You can see, therefore that the number of items with filenumber 0002 is not really a function of decay from those with number 0001, but instead the superposition of all a collection of ranges of files that include this number.
Staggering Number of Photographs
All these things being said, I am still a little surprised by the distribution. To me, there are a staggeringly large number of files with filenames at the top end of the range, such as IMG_9876 which has a frequency of over twenty thousand occurences. Because the curve is smooth (no sharp drop offs), and logarithmic in nature, there is nothing to suggest that large numbered filenames are not just part of an autonumbered sequence, so there must be plenty of prolific photographers who have taken tens of thousands of photos (the curve does not fall to zero, instead it falls to around 19,000 and then, presumably, these people have wrapped around the clock and started again!)
|
I like to take pictures of my family, but I don't have over 10,000! Digital cameras have certainly changed the way we, as a society, capture photographs. In the ‘old’ world of print film, care was taken to plan out a shot as the costs of production (both in terms of development costs and processing time) were large. Each roll of film typically had 36 exposures, so albumns were limited in size. These days, digital memory cards and storage costs are so low (and of such high capacity) that collection and compilation is only limited by your patience!
|
 |

Update
Thanks to some sleuthing by Shane Carroll, the IMG_0532 mystery has been solved! It appears that there is a flickr user(s) with multiple accounts and albumns who has been uploading thousands of copies of exactly the same images with, you guessed it, this filename!
You can find a complete list of all the articles here. Click here to receive email alerts on new articles.
Click here to receive email alerts on new articles.
© 2009-2013 DataGenetics