
Credit Cards
Most of us carry credit cards and ATM cards. These, typically, have sixteen digits on the front. These digits are the unique account number for the card. For obvious reasons, just any sixteen digits will not work, they follow pattern.
Here's a fictitious card I made up:

The first few characters of the card number describe the type of card.
Some cards are Visa, some Mastercard, some are American Express …
|
To the left is a (non-exhaustive) list of the some of the common card prefixes. Cards can be identified by their first few digits (try it out now, pull a few cards out of your wallet and look them up). (Here you can find a more complete list of Issue Identifier Numbers) |
Check Digits
Credit card numbers are often typed in, input, transferred and quoted. All of this transmission can cause errors, especially considering that humans are involved. Humans often make mistakes in transferal. To try and minimize this, credit card numbers contain a check digit.
In a typical sixteen digit credit card number, the first fifteen digits are determined by the issuing bank, but the last digit, called the check digit, is mathematically determined based on all the other digits.

You don’t select this last digit, it is deterministic. The exact mathematic formula for its generation was invented by Hans Peter Luhn, an engineer at IBM in 1954. Originally patented, the algorithm is now in the public domain and a Worldwide standard ISO/IEC 7812-1
 |
Obviously, with just a single check digit, not all errors can be detected (there’s a one in ten chance of a random number having the correct check digit), but the Luhn algorithm is clever in that it detects any single error (getting a single digit wrong), such as swapping the 9 with a 6 in the above example. It also detects almost all* pair-wise switching of two adjacent numbers. These errors are typical common errors people make when transcribing card numbers, so the check digit does a good thing. |
An added side benefit is that, as discussed above, there is only a one in ten chance that a randomly generated number has the correct check digit. This provides a small amount of protection from hackers or poorly educated crooks who might attempt to randomly generate and guess credit card numbers.
* It will not detect the switching of 09 to 90 (or vice versa)
The Luhn Algorithm
The Luhn algorithm is based around the principle of modulo arithmetic and digital roots.
The Luhn algorithm uses modulo-10 mathematics.
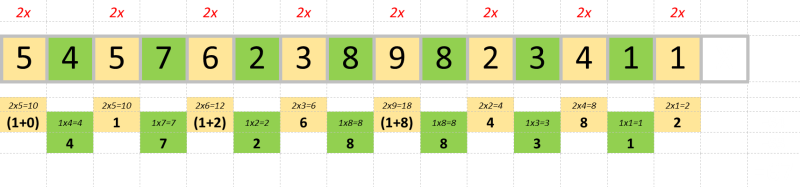
To calculate the check digit, multiply every even-position digit (when counted from the right) in the number by two. If the result is a two digit number, then add these digits together to make a single digit (this is called the digital root).
To this total, we then add every odd-position digit.
This will result in a total (in our example =67). The check-digit is what number needs to be added to this total to make the next multiple of 10. In our case, we’d need to add 3 to make 70. So the check-digit for this fictitious number is 3.
5457623898234113
(This is the same thing as asking what value the check-digit would need to be to make the sum mod 10 equal to zero. What number should be added to string to make a sum that, when divided by 10, gives no remainder.)
Try it for yourself!
Type a number into the box below and click the button to test:
Don't worry the numbers you type in are not being sent anywhere (if you are paranoid, you can view the source of the page to confirm). The script on the page is purely a client-side test to confirm the check digit is correct. This is common practice in the industry. Performing a client-side smoke-test to make sure things are well-formed before transmitting to the server is a good way to reduce load on your server.
Other uses
Adding a check digit is a very common practice to ensure that numbers are well-formed and have not fallen foul to a simply transcribing error, or unimaginative fraud.
|
Here are a selection of other common numbers have have check digits baked in (not all using Luhns Algorithm; there are a few other common encoding systems in use): Automobile VIN numbers, Barcodes, ISBN numbers on books and magazines, Australian Tax Numbers, Hungarian Social Security Numbers, American bank routing codes … For those interested in learning more, there are a couple of more complicated check digit algorithms than Luhn. These are the Verhoeff algorithm (1969) and the Damm algorithm (2004). These offer all the benefits of Luhn (detecting any single digit error), but also are able to detect any pair-wise adjacent transpositions of digits. There are also systems that are expanded to deal with errors in text and not just numbers. |
 |
Parity
The concept of check digits has been around for a long time. In the early days of computing, RAM was not as reliable as it is today. Computer designers wanted a way to detect hardware failures of memory.
 |
The solution they came up with was the concept of Parity. The eight bits that made up a byte were counted. The result was either an odd number of bits or an even number of bits. For every byte, one additional bit was generated. This was called the Parity Bit. The value of this parity bit was set based on the count of set bits and selected so that (typically) the number of bits set to the value 1 was even. This is called Even Parity. (It’s also just as possible to configure the system to maintain an odd number of bits. This is called Odd Parity. Both systems are perfectly acceptable, you simple choose which version you are going to use, and stick with it!) |
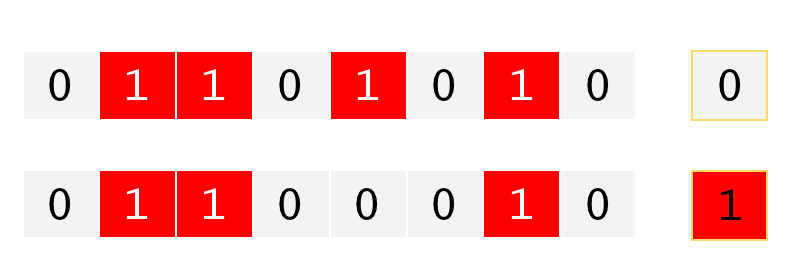
Whenever a value was read, at a hardware level, the parity was recomputed. If the parity was wrong, an error could be raised. You can clearly see how toggling of any single bit (flipping its state) would cause the parity to fail.
It would not tell you which bit had failed, just that one bit was wrong (it could even have been the parity bit that failed!)
|
RAM chips have become more reliable these days, and most modern PCs do not support parity RAM. High-end servers, however, and mission critical computers (banks, power stations …) still have hardware parity protection. In fact, they take this a step further and implement something called ECC (Error-Correcting Code memory). As mentioned above, simple parity just tells you something is wrong (and only if one thing goes wrong), but does not tell you what. This is incredibly valuable to know, but it does not help you fix things. This is where ECC comes in … |
 |
ECC memory works in a more complex way. It stripes information across a block of data. It is able to detect all errors of one-bit, and most errors of two simultaneous bits, but more crucially, is able to correct any single-bit error and put the correct value back. It is more complex than simply parity and requires multiple parity bits per byte (making it more expensive).
The math involved is quite complex, and outside the scope of this article, but relies on the concept of redundancy and storing information, mathematically, in more than one location. If you want to lean more, you can start here with information about Reed-Solomon Error Correction.
To show the basic concept, imagine the following scenario below with one unknown bit of information. If we can trust all the other bits, and we known that we are using even parity, we are able to repair the missing bit of information (in tha case the missing bit would need to be a zero).

RAID
A final example of the use of this damage tolerance from the tech industry is the RAID storage technology.
Spinning hard drives, being moving components, are typically the most fragile components in computer systems. Whilst the world is moving solid state rapidly, you’re either very young, very lucky, or have lived a sheltered life if you have not had firsthand experience of some kind of hard-drive failure.
Because data stored on hard drives is usually quite valuable, you want redundancy in storage. One solution is simply to ‘mirror’ the data on a parallel set of drives. This certainly works, but requires a doubling all the drives.
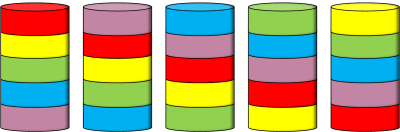 |
An alternative, and slightly more cost effective approach, is to use the principle of parity and stripe the data, and the parity, over a collection of drives. The theory is that, whilst one drive might fail, the probability of two drives failing at the same time is small. Once one drive is detected as going bad, then you can rely on the redundancy in the system to carry on running whilst you replace the bad drive. Once the new drive is installed, it can back-fill the parity and data and provide protection again, all without any downtime. |
RAID originally stood for “Redundant Array of Inexpensive Disks”, in reference to when hard drives were both expensive, and less reliable than they are today. When designed, the theory was to build arrays of cheap drives, knowing in advance that they would probably fail regularly, but by using cheaper drives, redundancy and replacement it was more cost effective than buying very expensive drives with slightly better reliability.
It was kind of like relying on a safety net.
These days, with reliability and technology improvements, we still have safety nets, but they are just that, safety nets, not standard operating procedure. To reflect this, the industry has changed the definition of RAID to now mean “Redundant Array of Independent Disks”
Check out other interesting blog articles here.
articles here.
You can find a complete list of all the articles here. Click here to receive email alerts on new articles.
Click here to receive email alerts on new articles.
© 2009-2013 DataGenetics Privacy Policy