
There are many ways to skin a cat
One of the things I like about mathematics puzzles is that there are, typically, multiple ways to solve the same problem. Sometimes you can use geometry, sometime trigonometry, sometimes algebra, sometimes calculus …
Because of the deterministic properties of mathematics, it does not matter the path you take to get to the solution. If you get the ‘correct’ answer, then everyone else who also solves the puzzle correctly gets the same answer.
Sometimes the tool you choose the solve a problem makes determining the solution super easy. Sometimes not.
On my Twitter feed, I often see puzzles posted by the incredibly talented Catriona Shearer (follow her now, if you don’t already. If you like my blog, I guarantee you will love her work). When I get time, I noodle on her puzzles. What fascinates me is the variety of ways that other people tackle them. Often there are incredibly elegant elucidations that collapse the problem flat to a something trivially easy. These solutions make me smile inside. Sometimes the right tool for the job really makes the task go easier, however, for a one-off problem, there’s no real wrong way to solve something.
There are many ways to skin a cat.
Wash-rinse-repeat
Things get more complicated when we need to repeat similar operations over and over again. Then we worry about efficiency. If you are trying to determine the number of boxes of small tiles you need to complete the remodel of your bathroom floor then accuracy is the primary consideration; how you get the answer is less important than the precision. However, if your job is a contractor, bidding for potential work, you might need to repeat this exercise dozens of times a month. Now you want speed (as well as keeping the accuracy).

Algorithms
This is really important when writing computer programs. The algorithm you select can have a massive impact on future performance and scaling. I used to work at Facebook; a site used by billions of people around the globe. A single 1% improvement to a core piece of code at Facebook could have a massive impact on the service:
- Billions of people might be able to access the site faster 1% faster!
- Millions of dollars of server costs could be saved over the lifetime of the improvement (and less power will be used by fewer machines, helping reduce the impact on the environment).
- People might be able to upload or download images of their friends and families just that little bit quicker (and if they were on paid mobile data plans, it might be cheaper for them to upload and download these images as less bytes need to be sent).
Code or tasks that need to be executed many times should, ideally, be as efficient as possible.
Big O notation
All of this hints to towards a subject studied in great detail by students of Computer Science: Time Complexity calculations (and it’s close cousin Space Complexity calculations), often referred to as ‘Big O’ notation as an indication of the worst case execution time for a particular algorithm. I’ll cover this in a second article, hopefully later this month.
Is it worth the time?
There's an excellent cartoon by XKCD, on which Ranadal has calculated the breakeven point between how much time you waste on a repetitive task (over five years), compared to how much time it's worth investing to automate this task.
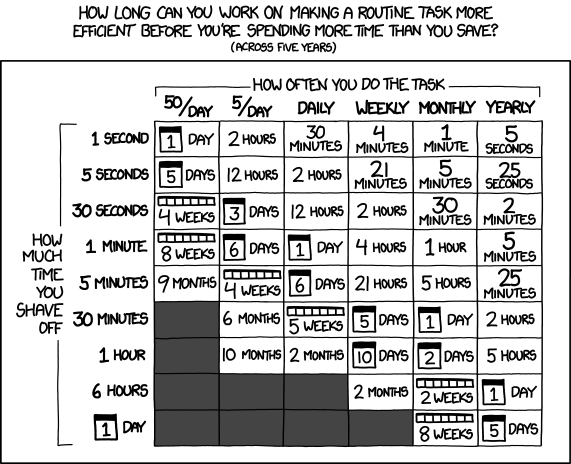
There's an important lesson here. Clearly, a core component in a loop that is executed millions of times should be made as efficient as possible, but when a task only gets executed rarely, 'good enough' is often more than acceptable. Modern computers are incredibly fast machines and capable of executing millions of (non-optimal) lines of code in the blink of an eye. For non-core functionality, different criteria come into play.
Given enough time, you can probably optimize the hell out of any piece of code, but when you do, other things suffer. Your goal should always be to write error-free code. A verbose algorithm might be less efficient, but it will probably be much easier to understand. If code is easier to understand, it is less likely to have errors in logic, edge cases, or plain simple mistakes. I'm not just talking about commented code, but code written in a way that makes comprehension of what is going on easier is going to have fewer errors. More relaxed code is probably easier to update and expand, and will definitely be more understandable by the person who follows you (potentially decades later), who has to debug or update your code. Compilers these days are also damn fine at optimizing your code for you; write readable code, and let the compiler do the hard work.
Overzealous optimization can lead you to make assumptions that aren't always valid, or remove vital error checking, as you chase the fantasy of more speed. On a large scale project, it can be a signal of poor project management, or poorly defined goals and criteria. Don't spend time finessing the details on your perfect first day honeymoon breakfast flower arrangement before you've started dating.
If speed really is mission critical, get the algorithm working first (and write all your test cases), before tackling optimization. Premature optimiztion is the root cause of so many problems, not just for the reasons above, but psychologically, it commits you to a path that because of the 'sunk cost fallacy' part of our brain makes people reluctant to change their course after 'investing' so much time in the path they are already along.
"Premature optimization is the root of all evil"- Donald Knuth
When writing (maintainable, and bug free) code, optimize only when needed, and as the last step.
Sorting
Sorting is an example of algorithms that have been optimized to within a hair’s breadth of their lives. Entire books have been written on the subject, and the tradeoffs between time and space complexity, and the suitability of a particular algorithm based on subtle hints you might know about the data to be sorted: Are they just numbers? Are they already somewhat in order? Do you care about preserving the order of non-unique elements? Is data being added as you are sorting? Is an approximation good enough? What happens if the sort terminates early because of some issue? Do we care about case sensitivity, or accented characters? What about null values? … Then are there hardware idiosyncrasies to take into account: What is the relative cost of a comparison between two values compared to swapping them? Are we sorting in place, or generating new output? Can the task be distributed to multiple machines? How much memory do we have to use? Are we allowed to only move an element once? …

I’ve not seen and update on this stat, but an old computer science textbook estimated the all the computers in the world spend approximately 25% of their non-idle time just sorting things. You can see why sorting is such a well-studied problem. Even a fractional percentage of an improvement could have a massive effect on the World.
Computers spend 25% of the their lives just sorting things!
Advertisement:
Four of a kind in Poker
The seed for this article was formed when I was thinking about all the different ways you could use to determine the probability of being dealt four-of-a-kind in a standard five card poker hand (no wild cards). Here are a couple of ways (there are many):

1: Combinatorics
There are 52C5 ways to draw a hand form a standard 52 card deck.
52C5 = 2,598,960
There are only 13 ranked cards [A,2,3, … J,Q,K], then there is the singleton left over, so each of these 13 sets can be matched with 48C1 possible other cards.
13C1 × 48C1 = 13 × 48 = 624 hands.
Pr(four_of_kind) = 624/2,598,960 = 1/4,165
2: Probability
Whatever the first card drawn (Pr=1), the chances that the second card drawn matches the rank of the first is 3/51. The chances the third matches is 2/50. The chance the fourth matches is 1/49, and we don’t care about the firth, so that is (Pr=1) also.
1 × 3/51 × 2/50 × 1/49 × 1 = 1/20,825
However, this last card could appear in any of the five positions, so we multiply by five.
Pr(four_of_a_kind) = 5 × 1/20,825 = 1/4,165
Two different ways to get to the same answer!
I love it how two totally different disciplines can be used to get the same result.
Misc
If you like thinking about four of a kind. How many cards would you need to have in a hand to guarantee you had at least one four of a kind?
If you want a more detailed analysis of probabilities all possible ranks of hand in five card poker, this article has all the answers (and gives explanations of the calculations).